La suma por reducción
Este código realiza la suma de un vector de N elementos mediante un operador binario de reducción, es decir, en log2(N) pasos. Suponemos un N suficientemente grande como para que requiera la comunicación intra-bloque e inter-bloque entre los hilos CUDA implicados en la computación.
Conceptos que pondremos en práctica
- Cómo alojar y liberar memoria en el dispositivo.
- Cómo copiar datos entre los distintos espacios de memoria.
- Cómo realizar la suma por reducción en la GPU.
- Realizar mediciones del tiempo de ejecución y los conflictos en el acceso a bancos de memoria compartida usando el CUDA profiler.
- Observar cómo los distintos esquemas de reducción afectan al número de conflictos en accesos a bancos de memoria compartida.
Cómo acceder a los ficheros fuente
Al igual que en el ejemplo básico, se proporcionan ficheros incompletos que el alumno debe rellenar. Pero en este caso, se proponen dos alternativas de dificultad creciente: La primera, dentro del directorio lab1.2-reduction.1, tiene menos líneas incompletas, y la segunda, colocada dentro del directorio lab1.2-reduction.2 tiene más. Digamos que los archivos de lab1.2-reduction.1 son un paso intermedio entre los de lab1.2-reduction.2 y la versión final que compila y ejecuta correctamente. Así, puedes comenzar con el índice de dificultad 2, y si ves que no sales adelante, conmutar al índice de dificultad 1. Además, cada versión incluye tres ficheros:
- vector_reduction.cu: Contiene el programa main() que aloja la memoria y llama al kernel CUDA.
- vector_reduction_kernel.cu: Contiene el kernel CUDA que se lanza desde el programa anterior.
- vector_reduction_gold.cpp: Es un programa C que computa el resultado secuencialmente en la CPU, para comprobar la validez de los cómputos realizados en paralelo en la GPU.
Reducciones
El objetivo de este ejercicio es familiarizarse con un tipo de operaciones muy común en computación científica: las reducciones. Una reducción es una combinación de todos los elementos de un vector en un valor único, utilizando para ello algún tipo de operador asociativo. Las implementaciones paralelas aprovechan esta asociatividad para calcular operaciones en paralelo, calculando el resultado en O(logN) pasos sin incrementar el número de operaciones realizadas. Un ejemplo de este tipo de operación se muestra en la siguiente figura:
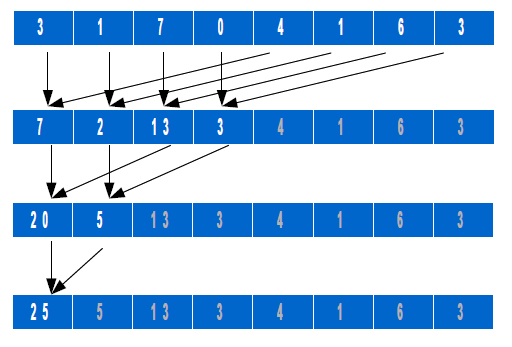
A partir de aquí, pueden idearse diferentes patrones de acceso a los datos para ir asociando por pares los operandos de cada operación. Esto afecta al rendimiento de la memoria como enseguida veremos, y también a la complejidad de programación, ya que las expresiones que hay que crear para que los hilos generen los índices de acceso a sus datos en cada paso difieren en dificultad.
Modificaciones a realizar sobre el código CUDA
Paso 1
Modi fica la función computeOnDevice(. . . ) de finida en el fichero vector_reduction.cu, para completar las siguientes operaciones:
- Reserva memoria en el dispositivo.
- Copia los datos de entrada desde la memoria del host hasta la memoria del dispositivo.
- Completa los parámetros de invocación al kernel (sólo si has escogido el índice de dificultad 2).
- Copia los resultados desde la memoria de dispositivo de vuelta a la memoria del host.
Paso 2:
En el fi chero vector_reduction_kernel.cu, modifi ca la función para implementar el esquema de reducción que hemos ilustrado en la figura anterior. Tu implementación debería usar memoria compartida para incrementar la eficiencia. Procede de la siguiente manera:
- Carga datos desde memoria global a memoria compartida (si has elegido el índice de dificultad 1, sólo tendrás que poner los índices a los vectores).
- Realiza la reducción sobre los datos en memoria compartida.
- Almacena de vuelta los datos en memoria compartida (sólo si has elegido el índice de dificultad 2).
Paso 3:
Una vez fi nalizado el código, compílalo con el comando make que utiliza el fichero Makefile, y luego lanza su ejecución desde la consola linux según se muestra a continuación. La versión sobre GPU se ejecutará siempre primero, seguida de la versión sobre CPU, que sirve como referencia para comprobar el resultado. Si el resultado es correcto, se imprime por pantalla el mensaje CORRECTO. En caso contrario, se imprime la frase INCORRECTO. El código se ejecuta sin argumentos, tomando como entrada un vector de datos de 512 elementos cuyos valores son aleatorios. La ejecución se realiza por tanto para 256 hilos, de la siguiente forma:
Paso 4 (opcional, en función del tiempo, pasaremos al Paso 5):
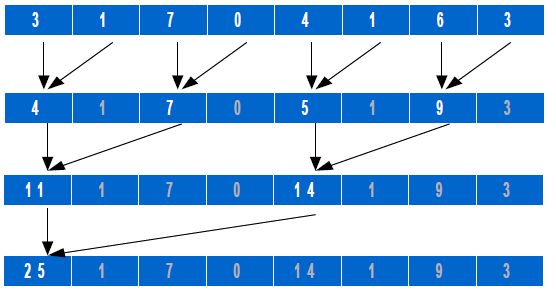
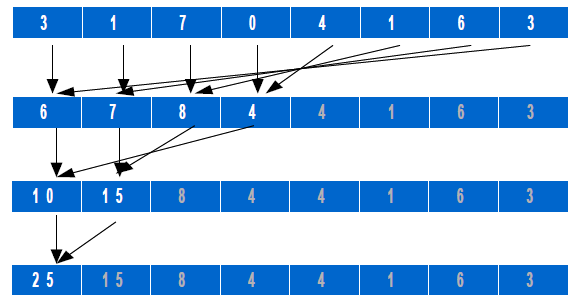
El hilo número 2 suma los elementos 2 y (8-1). La distancia correspondiente es pues 7-2 = 5. Y las
distancias para los nodos sumados por los hilos número 3 y 4 son 6-3 = 2 y 5-4 = 1, respectivamente.
patrones de este tipo para eliminar divergencias innecesarias o conflictos en accesos a bancos de memoria.
Paso 5:
Una vez fi nalizado el código, utiliza la siguiente secuencia de 5 comandos en tu shell del Linux para activar el CUDA pro filer:
$> CUDA_PROFILE=1
$> CUDA_PROFILE_CONFIG=./profile_config
$> export CUDA_PROFILE
$> export CUDA_PROFILE_CONFIG
$> ./vector_reduction
Por defecto, el fi chero de salida para el CUDA pro filer es cuda_profi le.log (también existe una versión gráfica del profiler, que en este caso no utilizaremos).
AVISO: En caso de que el fichero de salida anterior esté vacío, es porque la información que recopila el profiler se encuentra en sus buffers internos. Para forzar el volcado de esta información al fichero, coloca una llamada a la función cudaDeviceReset(); justo antes de que termine el programa. Luego vuelve a compilarlo todo y lanza de nuevo la ejecución. Una posible salida de la información del profiler es la siguiente:
# CUDA_PROFILE_LOG_VERSION 2.0
# CUDA_DEVICE 0 GeForce GTX 480
# TIMESTAMPFACTOR fffff7067548c2a0
method,gputime,cputime,occupancy,l1_shared_bank_conflict,shared_load,shared_store
method=[ memcpyHtoD ] gputime=[ 2.656 ] cputime=[ 5.000 ]
method=[ _Z9reductionPfi ] gputime=[ 7.680 ] cputime=[ 24.000 ] occupancy=[ 0.167 ] l1_shared_bank_conflict=[ 209 ] shared_load=[ 33 ] shared_store=[ 36 ]
method=[ memcpyDtoH ] gputime=[ 1.312 ] cputime=[ 14.000 ]
Los parámetros más interesantes del listado anterior son los siguientes:
- gputime muestra los microsegundos que necesita cada kernel CUDA para ser ejecutado.
- l1_shared_bank_conflict se refi ere al número de conflictos en el acceso a los bancos de la memoria compartida en la que ubicamos el vector scratch. En el ejemplo, no hay conflictos. Z9reductionPfi es el nombre dado por el runtime CUDA a la función reduction(. . . ).
- shared_load y shared_store se refieren al número de accesos en modo lectura y escritura en memoria compartida, respectivamente.
Compara los valores de l1_shared_bank_conflict y gputime para cada uno de los tres esquemas de reducción implementados. ¿Cuál de ellos es el más rápido?
| Esquema de reducción | Conflictos en los bancos de memoria compartida (l1_shared_bank_conflict) | Tiempo de ejecución (gputime) |
| 1 | ||
| 2 | ||
| 3 |
Existen multitud de contadores que podemos consultar para averiguar los puntos débiles de nuestro código. Si tienes curiosidad, puedes encontrar mucha más información en el fichero Compute_Profiler.txt de la máquina que estamos utilizando para desarrollo. En el caso de nuestra instalación local, ese fichero se encuentra en el directorio /usr/local/cuda/doc, donde por cierto también encontrarás muchos PDFs y documentación anexa que te puede ser de utilidad.